全栈工程 · RAG 系统
Legal RAG — 法律智能问答系统
基于检索增强生成的法律知识问答系统,支持法律条文检索、案例匹配、Agent 自主分析,从后端到前端的全栈实现。
系统截图
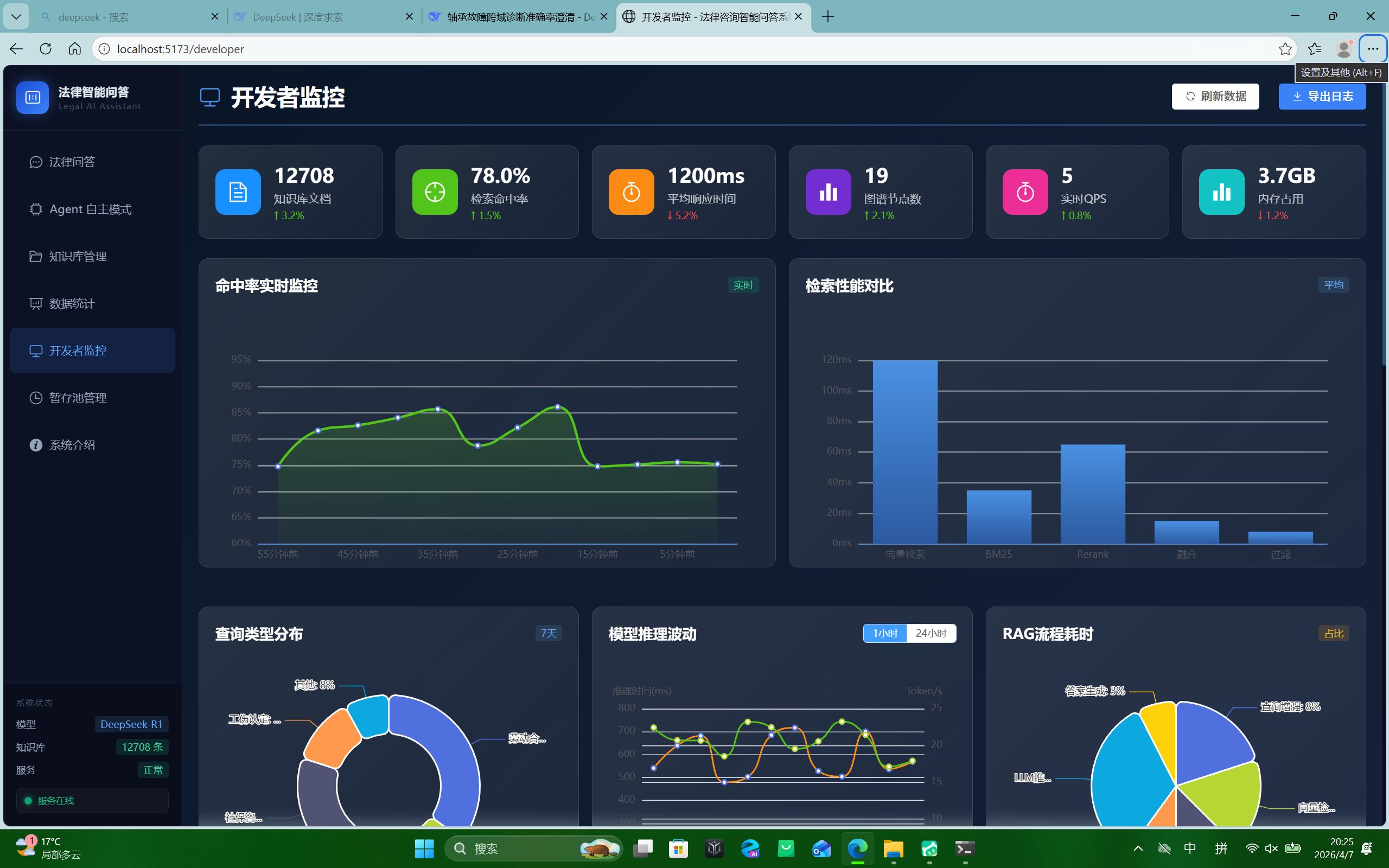
开发者监控面板 — 命中率实时曲线、RAG 流程耗时分布、模型推理波动追踪
核心挑战:OOM 崩溃与检索融合
项目初期面临两个核心问题:一是 60+ 法律文档一次性加载全部 chunk 再统一向量化导致 OOM(Out of Memory)崩溃;二是 BM25 关键词检索和向量语义检索的分数量纲不同,无法直接加权融合。解决方案:
- 分批入库策略:逐文件加载、每 5 个文件批次写入向量库、GC 及时释放内存,彻底解决 OOM 问题
- RRF 融合(Reciprocal Rank Fusion):用排名倒数融合替代分数加权,对两路分数量纲差异天然免疫
- 双通道降级设计:Ollama 不可达时自动降级为纯 BM25 检索,确保系统始终可用
SSE 流式输出 + 知识图谱
RAG 管线输出通过 Server-Sent Events 实时流式推送到前端,用户体验上无需等待完整生成。知识图谱采用纯 Python 邻接表实现(无需额外图数据库依赖),在文档入库时同步构建实体关系网络,支持概念追溯和法律条文关联查询。前端展示中,每条引用都标注了原始来源和置信度。
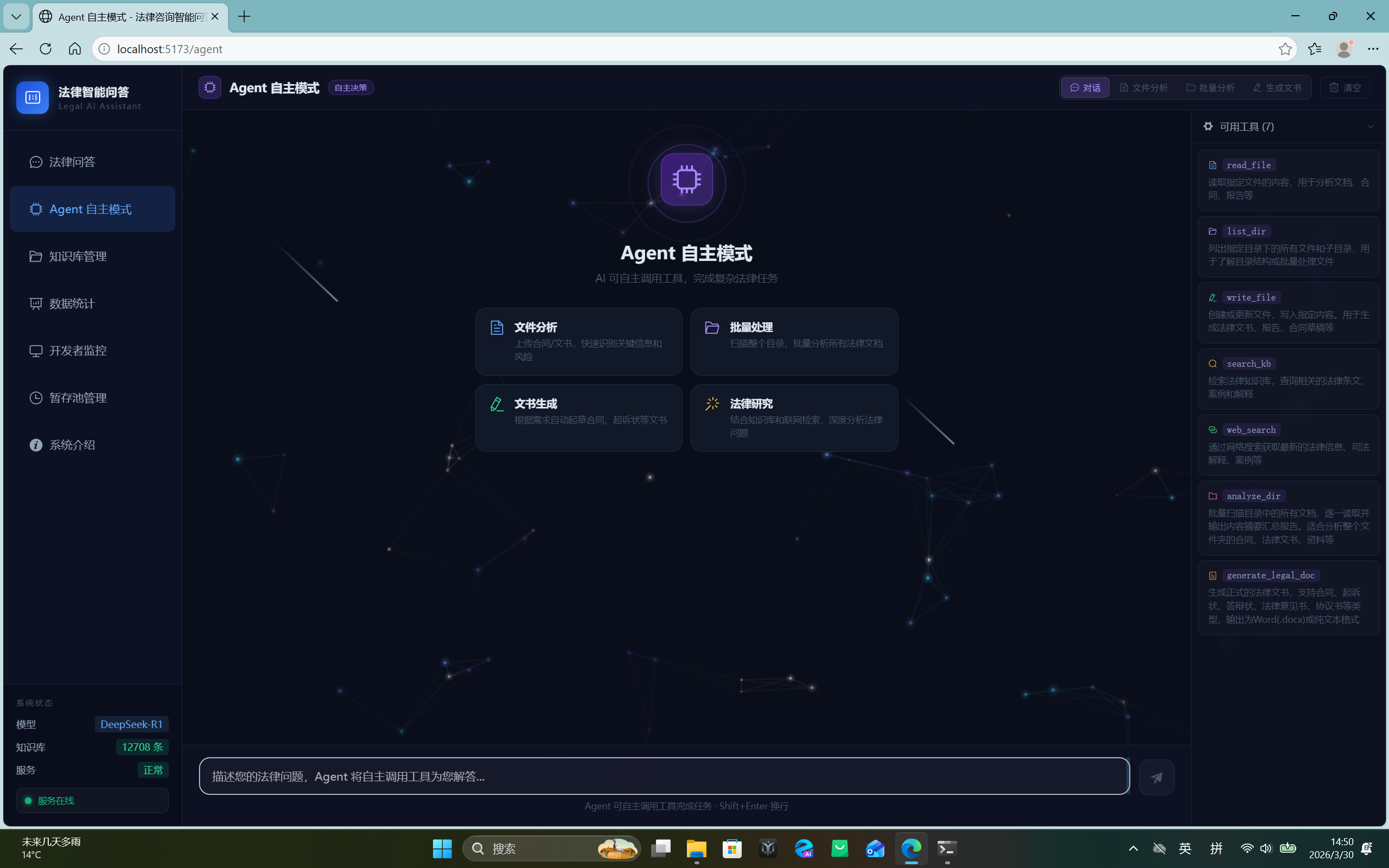
Agent 自主模式
系统内置 Agent 能力层,支持 LLM 自主调用工具链:文件读取/写入、代码执行、网页搜索、法律文书生成。工具注册表(ToolRegistry)统一管理所有可用工具,Agent 根据用户意图动态规划调用序列。前端提供可视化的步骤时间线(thinking → tool_call → tool_result),让用户清晰感知 Agent 的思考过程。
技术栈
FastAPI Vue 3 RAG 管线 RRF 融合 SSE 流式 知识图谱 Ollama / DeepSeek BGE-M3 嵌入